스프링 핵심 기술의 응용
지금까지 스프링의 3대 기술인 IoC/DI, 서비스 추상화, AOP에 대해 간단히 살펴보았습니다. 이 기술들은 결국 객체지향 기술입니다. 7장에서는 세 가지 기술을 활용해서 새로운 기능을 만들어보고, 스프링의 추구하는가치를 살펴봅니다.
1. SQL과 DAO의 분리
우리는 JDBC작업 흐름을 인터페이스와 템플릿으로 UserDao에서 분리해냈습니다. 트랜잭션과 예외처리 작업도 서비스 추상화와 AOP 등을 처리해서 분리했습니다. 조금더 욕심을내서 변하면서 DAO가 관심을 갖지 않는 부분인 SQL을 분리해 낼 수 있습니다.
1-1. XML 설정을 이용한 분리
간단하게 sql문을 userDao의 필드로 추가하고 xml설정을 이용해 DI받도록 설정할 수 있습니다. 메소드에 따라 SQL문이 점점 많아질 것이므로, SQL문을 하나로 모아두는 방식을 활용합니다. 필드를 map타입으로 선업합니다.
// UserDaoJDBC 클래스
private map<String, String> sqlMap;
public void setSqlMap(Map<Stirng, String> sqlMap){
this.sqlMap=sqlMap;
}
public void add(User user){
this.jdbcTemplate.update(
this.sqlMap.get("add"); // 키를 이용해서 필요한 SQL을 가져옵니다.
)
}
// xml 설정
<bean id="userDao" class="springbook.user.dao.UserDaoJdbc">
<property name="dataSource" ref="dataSource" />
<property name="sqlMap">
<map>
<entry key="add" value="insert into users(id, name, password, email, level, login, recommend) values(?,?,?,?,?,?,?)" />
<entry key="get" value="select * from users where id = ?" />
<entry key="getAll" value="select * from users order by id" />
<entry key="deleteAll" value="delete from users" />
<entry key="getCount" value="select count(*) from users" />
<entry key="update" value="update users set name = ?, password = ?, email = ?, level = ?, login = ?, recommend = ? where id = ?" />
</map>
</property>
</bean>
1-2. SQL 제공 서비스
다만 애플리케이션 구성정보를 가진 xml에 SQL 문장을 두는것은 바람직 하지 못합니다. 싱글톤인 DAO 인스턴스 변수에 접근해서 내용을 수정하는 것도 어렵습니다. 그래서 독립적인 SQL 제공 서비스가 필요합니다.
SQL 서비스의 인터페이스를 설명합니다. 늘 해왔던 인터페이스로 추상화하고 구현 클래스를 DI하는 것입니다. DAO는 어떤 키값으로 SQL 서비스를 이용할 것인지만 알면 됩니다.
public interface SqlService{
String getSql(String key) throws SqlRetrievalFailureException;
// 런타임 예외입니다.
}
// 구현 클래스입니다.
public class SImpleSqlService implements SqlService{
private Map<String, String> sqlMap;
public void setSql... // 세터 메소드
@Override
public String getSql(String key) throws ...{
String sql = sqlMap.get(key);
if (sql == null) throws new ...;
else return sql;
}
}
// UserDaoJDBC에 DI받을 수 있도록 SqlService 타입 필드를 추가합니다.
// UserDaoJDBC의 모든 메소드가 sqlService.getSql로 sql을 가져오도록 수정합니다.
public void add(User user) {
this.jdbcTemplate.update(
this.sqlService.getSql("userAdd"),
user.getId(), user.getName(), user.getPassword(), user.getEmail(),
user.getLevel().intValue(), user.getLogin(), user.getRecommend());
}
...
// xml 설정입니다.
<bean id="userDao" class="springbook.user.dao.UserDaoJdbc">
<property name="dataSource" ref="dataSource" />
<property name="sqlService" ref="sqlService" />
</bean>
<bean id="sqlService" class="springbook.user.sqlservice.SimpleSqlService">
<property name="sqlMap">
<map>
<entry key="userAdd" value="insert into users(id, name, password, email, level, login, recommend) values(?,?,?,?,?,?,?)" />
<entry key="userGet" value="select * from users where id = ?" />
<entry key="userGetAll" value="select * from users order by id" />
<entry key="userDeleteAll" value="delete from users" />
<entry key="userGetCount" value="select count(*) from users" />
<entry key="userUpdate" value="update users set name = ?, password = ?, email = ?, level = ?, login = ?, recommend = ? where id = ?" />
</map>
</property>
</bean>
2. 인터페이스의 분리와 자기참조 빈
2-1. XML 파일 매핑
여전히 xml파일에 sql문을 넣는 것은 좋은 방법이 아닙니다. SQL을 저장해두는 전용 포맷을 가진 독립적인 파일을 이용하는 편이 바람직합니다. 물론 독립적으로 만든 XML파일이 가장 편리한 포맷입니다. JAXB(Java Architecture for XML Binding)은 XML에 담긴 정보를 파일에서 읽어오는 간단한 방법입니다. DOM(문서 객체 모델, 문서 내의 요소를 정의하고 접근하는 방법을 제시)은 XML의 정보를 리플랙션 방식처럼 간접적으로 접근하지만, JAXB는 XML 정보를 오브젝트 처럼 직접 다룹니다. 또, 스키마를 이용해서 매핑할 오브젝트의 클래스까지 자동으로 만들어줍니다. 이때 매핑정보는 어노테이션으로 담겨있습니다.
JAXB API 를 이용해 xml을 자바의 오브젝트로 변환하는 것을 unmarshalling(언마샬링)이라고 부릅니다. 반대는 마샬링 입니다. 자바 오브젝트를 바이트 스트림으로 바꾸는 것을 직렬화(serialization)이라 부르는 것과 비슷합니다.
// 스키마입니다.
<schema xmlns="...w3.org/20001XMLSchema">
...
<element name="sqlamp"> // <sqlmap> 앨리먼트를 정의합니다.
<complexType>
<sequence>
<element name="sql" maxOccurs="unbounded" type="tns:sqlType" /> // unbounded : 필요한 개수만큼 <sql>을 포함할 수 있게 합니다
...
<complexType name="sqlType"> // <sql>에 대한 정의 입니다.
<simpleContent>
<extension base="string"> //sql 문장을 넣을 타입입니다.
<attribute name="key" use="required" type="string" /> // <sql>의 key 애트리뷰트는 반드시 입력해야합니다. 값은 string입니다.
...
// sqlmap.xsd라는 이름으로 프로젝트 루트에 저장하고 JAXB 컴파일러로 컴파일 합니다.
// 터미널
xjc -p springbook.user.sqlservice.jaxb sqlmap.xsd -d src
// 생성할 클래스의 패키지 주소 / 변환할 스키마 파일 / 생성된 파일이 저장될 위치로 src로 지정
// 이후 컴파일러가 만들어준 xml 바인딩용 클래스 SqlType.java 와 Sqlmap.java가 만들어집니다.
// SqlType 은 필드로 value와 key를 가져 <sql>태그 한개당 오브젝트 하나가 만들어집니다.
// Sqlmap클래스는 <sql>태그의 정보를 담은 SqlTpye 오브젝트를 리스트로 갖고있습니다.
JAXB의 작동방식은 아래와 같습니다.

2-2. xml 파일을 이용하는 SQL 서비스
이제 UserDaoJdbc에서 사용할 SQL이 담긴 xml 파일을 만들어봅니다. SQL은 DAO로직의 일부라고 볼 수 있으므로 DAO와 같은 패키지에 두도록 합니다. sqlmap.xml이라는 이름으로 UserDao와 같은 패키지에 둡니다.
<?xml version="1.0" encoding="UTF-8"?>
<sqlmap xmlns="http://www.epril.com/sqlmap" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.epril.com/sqlmap http://www.epril.com/sqlmap/sqlmap.xsd ">
<sql key="userAdd">insert into users(id, name, password, email, level, login, recommend) values(?,?,?,?,?,?,?)</sql>
<sql key="userGet">select * from users where id = ?</sql>
<sql key="userGetAll">select * from users order by id</sql>
<sql key="userDeleteAll">delete from users</sql>
<sql key="userGetCount">select count(*) from users</sql>
<sql key="userUpdate">update users set name = ?, password = ?, email = ?, level = ?, login = ?, recommend = ? where id = ?</sql>
</sqlmap>
다음은 sqlmap.xml에 있는 sql을 갖와 DAO에 제공해주는 SqlService 인터페이스의 구현 클래스를 만듭니다. 언제 JAXB를 사용해 xml문서를 가져올 지를 생각해야 합니다.
DAO가 매번 요청할 때마다 xml파일을 읽는 것은 비효율 적입니다. SqlService 빈은 스프링이 관리 할 것이므로 언제 어떻게 생성될지 알 수 없습니다. 우선은 간단히 생성자에서 SQL을 읽어와 맵으로 저장해서 요청에 따라 SQL을 전달하도록 만듭니다.
public class XmlSqlService implements SqlService {
private Map<String, String> sqlMap = new HashMap<String, String>();
// SQL들을 읽어와서 저장해둘 곳입니다.
public void xmlSqlService() {
// 생성자를 이용해 스프링이 오브젝트를 만드는 시점에서 SQL을 읽어오도록 합니다.
String contextPath = Sqlmap.class.getPackage().getName();
// 전에 스키마 컴파일러로 만들어둔 Sqlmap클래스를 이용합니다.
try {
JAXBContext context = JAXBContext.newInstance(contextPath);
// JAXB API를 사용하기 위해 컨텍스트를 생성합니다.
Unmarshaller unmarshaller = context.createUnmarshaller();
// 언마샬러 생성
InputStream is = UserDao.class.getResourceAsStream("sqlmap.xml");
// userDao와 같은 경로의 sqlmap.xml 파일을 변환합니다.
Sqlmap sqlmap = (Sqlmap)unmarshaller.unmarshal(is);
// JAXB API를 이용해 XML 문서를 오브젝트 트리로 읽어옵니다.(언마샬)
for(SqlType sql : sqlmap.getSql()) {
sqlMap.put(sql.getKey(), sql.getValue());
}
// 읽어온 SQL을 맵으로 저장합니다.
} catch (JAXBException e) {
throw new RuntimeException(e);
}
}
public String getSql(String key) throws SqlRetrievalFailureException {
String sql = sqlMap.get(key);
if (sql == null)
throw new SqlRetrievalFailureException(key + "�� �̿��ؼ� SQL�� ã�� �� �����ϴ�");
else
return sql;
}
}
// 빈설정
<bean id="sqlService" class="XmlSqlService 경로">
이제 SQL 문장을 스프링의 빈 설정에서도 완벽하게 분리했습니다. 필요하다면 SQL 문장을 정의한 xml 파일로 다른 툴에서 사용할 수 있습니다.
2-3. 빈의 초기화 작업
개선할 점은 여전히 있습니다. 우선 생성자에서 예외발생 가능성이있는 복잡한 초기화 작업을 다루는 것은 좋지 않습니다. 상속하기도 불편하고 보안에도 문제가 생깁니다.
일단 초기 상태를 가진 오브젝트를 만들어놓고 별도의 초기화 메소드를 사용하는 방법이 바람직합니다. 또, 읽어들일 파일의 위치와 이름이 코드에 고정되게 됩니다. 바뀔 가능성이 있는 내용은 외부에서 DI로 설정해줄 수 있게 해야합니다.
public class XmlSqlService implements SqlService {
private Map<String, String> sqlMap = new HashMap<String, String>();
private String sqlmapFile;
// 맵 파일을 외부에서 지정할 수 있도록 필드를 추가합니다.
// xml 설정은 생략
public void setSqlmapFile(String sqlmapFile) {
this.sqlmapFile = sqlmapFile;
}
@PostConstruct // 아래 설명 참조
public void loadSql() { // 별도의 초기화 메소드입니다.
String contextPath = Sqlmap.class.getPackage().getName();
try {
JAXBContext context = JAXBContext.newInstance(contextPath);
Unmarshaller unmarshaller = context.createUnmarshaller();
InputStream is = UserDao.class.getResourceAsStream(this.sqlmapFile);
// DI 받은 파일 이름을 사용합니다.
Sqlmap sqlmap = (Sqlmap)unmarshaller.unmarshal(is);
...
}
loadSql()이라는 초기화 메소드는 오브젝트를 만드는 시점에서 초기솨 메소드를 한 번 호출하면 됩니다. 문제는 빈 이므로 제어권이 스프링에게 있습니다. 생성은 물론 초기화도 스프링에게 맡길 수 밖에 없습니다. 그래서 스프링은 미리 지정한 초기화 메소드를 호출해주는 기능을 갖고 있습니다. 전에 사용했던 빈 후처리기 중에 어노테이션을 이용한 빈 설정을 지원해주는 빈 후처리기가 있습니다. context 스키마의 annotation-config 태그를 이용하면 편리합니다. context의 네임스페이스와 스키마를 지정해주면 어노테이션을 이용해서 부가적인 빈 설정 또는 초기화 작업을 도와주는 후처리기를 등록하게 됩니다.
@PostConstruct를 이용하면 빈 오브젝트의 초기화 메소드로 지정합니다. 빈 오브젝트를 생성하고 DI작업을 마치고 초기화 작업을 실행해 줍니다. 즉, 프로퍼티까지 모두 준비된 후에 실행된다는 것입니다.
2-4. 변화를 위한 준비: 인터페이스 분리
xmlSqlService는 아직 확장할 영역이 많이 있습니다. 만약 xml대신 다른 포맷의 파일에서 SQL을 읽어오게 하려면 지금 구조에서는 완전히 뜯어 고쳐야합니다. 즉, SQL을 가져오는 방법이 고정되어 있습니다. 만약 HashMap이 아닌 다른 방식으로 저장해서 가져오려면 역시 새로 작성해야 합니다. 이는 단일 책임 원칙을 위반합니다. 그렇다고 아예 새로운 클래스를 만들면 상단 부분의 코드가 중복됩니다. 늘 그래왔듯 인터페이스와 DI를 이용합니다.
분리 가능한 관심사를 생각해봅니다.
- SQL정보를 외부의 리소스로부터 읽어오는 것입니다. –> SqlReader 클래스
- 읽어온 SQL을 저장하고 호출할 때 제공하는 것입니다. 부가적인 책임으로 가져온 SQL을 런타임시에 수정하는 기능도 생각해 볼 수 있습니다. –> SqlRegistry 클래스
이 두책임을 어떻게 조합할 것인지 생각해봅니다.
- SqlService를 구현해서, 인터페이스로 DAO와 의존관계를 맺습니다.
- DAO에 서비스를 제공해주는 오브젝트(userService)와 이 두가지 책임을 가진 오브젝트를 협력해서 동작하도록 합니다.
인터페이스를 구현하기 전에 생각해 볼 점이 있습니다. sqlReader로 읽어온 sql을 어떻게 sqlRegistry로 전달해새 저장할 것인지를 생각해야합니다. sqlReader의 메소드의 리턴 타입을 map으로 지정해서 전달하면, 만약 JAXB에서 읽어올 경우, sqlmap과 sqp타입 오브젝트로 읽어온 정보를 다시 map으로 옮겨 닮아서 리턴하게 되서 불편합니다. 그렇다고 JAXB의 sql 클래스를 리턴타입으로 쓰면, JAXB 기술에 고정되어버리게 됩니다. 우리는 구현 방식이 다양한 두 개의 오브젝트 사이에서 포맷을 강제하는 것을 피할 방법을 찾아야 합니다.
발상을 조금 바꿔 보면 이런 번거로움을 제거할 방법이 있습니다.
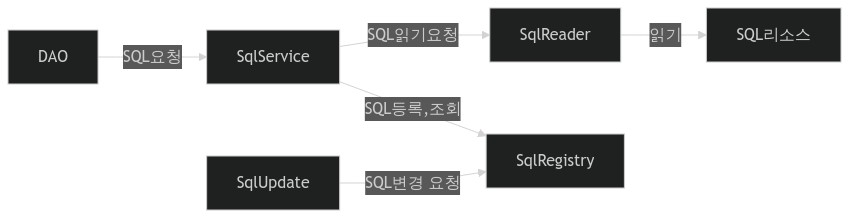
본래 SqlReader로 읽어온 정보를 SqlService구현 클래스를 통해 SqlRegistry에게 전달하는 구조였습니다. 하지만 단순히 두 오브젝트(리더,레지스트리) 사이의 정보를 전달하는 것이 전부라면 SqlService가 중간 과정에서 빠지는 방법을 생각해 볼 수 있습니다.
즉, SqlReader에게 SQlRegistry 전략을 제공해주면서 저장하라고 요청하게 하는 것입니다.

이런 구조로 만들면 불필요하게 SqlService의 코드를통해 특정 포맷으로 변환한 SQL정보를 주고 받을 필요가 없습니다. SqlReader와 SqlRegistry는 각자의 구현 방식을 독립적으로 유지하면서 꼭 필요한 관계만 가지고 협력합니다.
SqlRegistry가 일종의 콜백 오브젝트가 되면서 SqlReader가 사용할 SqlRegistry의 오브젝트를 제공하는것을 SqlService가 담당합니다.
SqlReader는 내부에 갖고 있는 데이터(SQL정보)를 의존 오브젝트인 SqlRegistry의 필요에 따라(등록할 때만) 돌려줍니다.
자바 오브젝트는 쓸데없이 자신 내부의 데이터를 외부로 노출시킬 필요가 없습니다.
코드로 살펴봅니다.
// 기존에 SqlService를 사이에 두고 정보를 주고받을 경우
public class SqlService구현 implements SqlService{
Map<String,Sring> sqls = sqlReader.readSql();
// 맵이라는 전송타입을 강제하게됩니다.
sqlRegistry.addSqls(sqls);
}
// SqlReader와 SqlRegistry 사이에 의존 관계를 둘경우
public class SqlService구현 implements SqlService{
sqlReader.readSql(sqlRegistry);
}
interface SqlRegistry{
void registerSql(String key, String sql);
// SqlReader가 이 메소드를 이용해 읽어들인 SQL을 SqlRegistry에 저장합니다.
String findSql(String key) throws SqlNotFoundException;
// 키로 SQL을 검색합니다. 검색 실패시 예외를 던집니다.
}
interface SqlReader{
void readSql(SqlRegistry sqlRegistry);
}
이제 두 개의 책임에 대한 인터페이스를 정의했습니다. 이 확장구조를 담는 SqlService 구현 클래스는 두 개의 인터페이스 타입 프로퍼티를 갖고 DI받도록 합니다.
2-5. 자기참조 빈으로 시작하기
기존에 만든 SqlService의 구현 클랫 XmlSqlService를 다시 보면, SqlService, SqlReader, SqlRegistry 이 세 관심사를 구분 없이 하나로 모아놨었습니다. 그렇다면 이 세 개의 인터페이스를 XmlSqlService 하나의 클래스가 모두 구현하는 것도 괜찮습니다. extends의 상속과 달리 implements는 다중 상속이 가능합니다. 인터페이스 구현 역시 상속의 일종으로 타입을 상속받게 됩니다. 또, 클래스는 당연히 인터페이스에만 의존하게 만들어야 DI를 적용해 구현 클래스를 바꾸고 의존 오브젝트를 변경해서 자유롭게 확장할 수 있습니다.
이제부터 할 것은 책임에 따라 분리되지 않았던 코드가 모인 XmlSqlService 클래스를 책임에 따라 분리된 인터페이스를 구현하도록 만드는 것입니다. 그래서 같은 클래스의 코드지만, 책임이 다른 코드는 직접 접근하지 않고 해당 인터페이스를 통해 간접적으로 사용하도록 합니다.
public class XmlSqlService implements SqlService, SqlRegistry, SqlReader {
// --------- SqlProvider ------------
private SqlReader sqlReader;
private SqlRegistry sqlRegistry;
// 의존 오브젝트를 DI받을 수 있도록 선언합니다.
public void setSqlReader(SqlReader sqlReader) {
this.sqlReader = sqlReader;
}
public void setSqlRegistry(SqlRegistry sqlRegistry) {
this.sqlRegistry = sqlRegistry;
}
@PostConstruct
public void loadSql() {
this.sqlReader.read(this.sqlRegistry);
// 초기화 메소드에서는 sqlReader에게 sqlRegistry를 전달해서 읽고 저장하게 합니다.
// 어떻게 구현할지는 의존 오브젝트의 역할입니다.
}
@Override
public String getSql(String key) throws SqlRetrievalFailureException {
try {
return this.sqlRegistry.findSql(key);
// sqlService의 메소드입니다. Registry와 key값을 이용해 가져옵니다.
}
catch(SqlNotFoundException e) {
throw new SqlRetrievalFailureException(e);
}
}
// --------- SqlRegistry ------------
private Map<String, String> sqlMap = new HashMap<String, String>();
// SqlRegistry 구현의 일부므로 SqlRegistry 구현 메소드로만 접근합니다.
@Override
public String findSql(String key) throws SqlNotFoundException {
String sql = sqlMap.get(key);
if (sql == null)
throw new SqlRetrievalFailureException(key + "에 대한 SQL을 찾을 수 없습니다.");
else
return sql;
}
@Override
public void registerSql(String key, String sql) {
sqlMap.put(key, sql);
// HashMap 저장소를 사용하는 구현방법에서 독립되기 위해 인터페이스의 메소드로 접근합니다.
// SQL을 등록할 때는 Reader를 이용해 등록 됩니다.
}
// --------- SqlReader ------------
private String sqlmapFile;
// sqlReader 구현의 일부므로 sqlReader의 구현 메소드로만 접근합니다.
public void setSqlmapFile(String sqlmapFile) {
this.sqlmapFile = sqlmapFile;
}
@Override
public void read(SqlRegistry sqlRegistry) {
String contextPath = Sqlmap.class.getPackage().getName();
try {
JAXBContext context = JAXBContext.newInstance(contextPath);
Unmarshaller unmarshaller = context.createUnmarshaller();
InputStream is = UserDao.class.getResourceAsStream(sqlmapFile);
Sqlmap sqlmap = (Sqlmap)unmarshaller.unmarshal(is);
for(SqlType sql : sqlmap.getSql()) {
sqlRegistry.registerSql(sql.getKey(), sql.getValue());
}
} catch (JAXBException e) {
throw new RuntimeException(e);
}
}
}
//bean 설정
<bean id="sqlService" class="XmlsqlService 경로">
<property name="sqlReader" ref="sqlService" />
<property name="sqlRegistry" ref="sqlService" />
<property name="sqlmapFile" ref="sqlmap.xml" />
// 프로퍼티는 자기 자신을 참조 할 수 있습니다. 수정자 메소드로 주입만 가능하면 됩니다.
이렇게 세 기능을 인터페이스로 분리하고, JAXB를 사용하는 SqlReader와 HashMap을 사용하는 SqlRegistry와 sqlService를 한 곳으로 모은 구현 클래스를 만들었습니다.
SQL을 읽을 때는 SqlService가 reader를 통하고 찾을 떄는 registry를 통합니다. sql을 등록할때는 reader가 DI받은 registry에 등록합니다.
2-6. 디폴트 의존관계
반면 확장을 위해 세 관심사를 완전 분리해서 각각 구현 클래스를 두고 DI로 조합하는 방법도 생각해 볼 수 있습니다. 이떄 SqlService 구현 클래스의 프로퍼티(리더, 레지스트리)들을 서브클래스에서 필요한 경우에만 접근할 수 있도록 protected로 선언합니다. 다만 이럴 경우 빈 설정이 늘어나게 됩니다. 만약, 특정 의존 오브젝트가 대부분의 환경에서 거의 기본적으로 사용될 가능성이 있다면, 디폴트 의존관계를 갖는 빈을 만드는 것도 고려해볼 수 있습니다.
디폴트 의존관계 : 외부에서 DI받지 않는 경우에 자동 적용되는 의존관계를 말합니다.
public class DefaultSqlService extends BaseSqlService{
// SqlService만 구현한 클래스를 상속받은 클래스 입니다.
public DefaultSqlService(){
setSqlReader(new JaxbXmlSqlReader());
setSqlRegistry(new HasnMapSqlRegistry());
// 각각 따로 구현한 리더와 레지스트리 클래스
}
}
// 빈설정
<bean id="sqlService" class="DeefalutSqlService경로">
// sqlamp 프로퍼티도 디폴트 의존관계를 맺어야하는데 이 프로퍼티는
// reader에서 갖고있으므로 reader역시 디폴트 의존관계를 만듭니다.
pulbic class JaxbSqlReader implements SqlReader{
private static final String DEFAULT_SQLMAP_FILE = "sqlamp.xml";
// 상수로 디폴트 값을 줍니다.
private String sqlmapFile = DEFAULT_SQLMAP_FILE;
...
}
DefaultSqlService는 BaseSqlService를 상속받으므로, 부모의 프로퍼티를 그대로 갖고있습니다. 이를 이용해 언제든지 프로퍼티를 변경할 수 있습니다. 디폴트 의존 오브젝트 대신 다른 오브젝트를 사용하려면 빈 설정으로 추가하면 됩니다. 다만 이럴경우, 생성자에서 빈을 만들고 다시 대신 사용할 빈을 만들기 때문에 리소스 낭비가 있을 수 있습니다.
3. 서비스 추상화 적용
JaxbXmlSqlReader는 조금 더 개선해야 할 부분이 있습니다.
- JAXB기술 외에도 다른 기술로도 손쉽게 바꿔 사용할 수 있어야 합니다.
- 같은 클래스패스 안에서만 XML을 읽어오는 것을, 원격이나 절대경로로도 읽어올 수 있어야 합니다.
3-1. OXM 서비스 추상화
JAXB외에도 Object-XML Mapiing 기술은 여러 개가 있습니다. 여러가지 기술이 존재한다면 서비스 추상화가 떠오르비다. 스프링은 트랜잭션, 메일 전송 뿐만아니라 OXM에 대해서도 서비스 추상화 기능을 제공합니다. Mashaller 인터페이스와 Unmarshaller 인터페이스 입니다. 이 두가지를 모두 구현한 클래스로 Jaxb2Marshaller가 있습니다. 빈으로 해당 클래스를 unmarshaller 라는 id로 추가합니다. 해당 빈은 Unmarshaller 타입이므로 @Autowired로 주입이 가능합니다. 다른 기술로 바꾸고싶다면 빈의 클래스를 해당 기술의 구현 클래스로 변경해주면 됩니다. 이렇게 구성하면 어떤 구현 클래스 이든 unmarshal()한줄이면 언마샬링이 끝납니다.
3-2. OXM 서비스 추상화 적용
이제 OXM 추상화 기능을 사용하는 SqlService를 만들어 봅니다. SqlReader는 스프링의 OXM 언마샬러을 이용하도록 OxmSqlService내에 고정시킵니다. SQL을 읽는 방법을 OXM으로 제한해서 사용성을 극대화(최적화) 합니다. Reader클래스를 스태틱 맴버 클래스로 정의하면 의존 오브젝트를 자신만 사용하도록 독점합니다. 이는 낮은 결합도를 유지하면서 높은 응집도를 구현합니다. 이렇게 OxmSqlService와 OxmSqlReader는 구조적으론 결합, 논리적으로는 명확하게 분리됩니다. 스태틱 맴버 클래스는 이런 용도로 씁니다.
public class OxmSqlService implements SqlService {
private final OxmSqlReader oxmSqlReader = new OxmSqlReader();
// final로 설정해서 상속과 확장이 불가능합니다. Service와 Reader는 강하게 결합돼서 하나의 빈으로 등록되고 한번에 설정합니다.
// final로 선언해서 한번만 초기화 하게 됩니다. 즉 Service생성과 Reader가 생성 되서 초기화됩니다.
private SqlRegistry sqlRegistry = new HashMapSqlRegistry();
// private 맴버 클래스로 정의 합니다. 그러면 OxmSqlService만이 사용할 수 있습니다.
// reader와 달리 디폴트 오브젝트로 만들어진 프로퍼티 입니다. 교체 가능합니다.
public void setSqlRegistry(SqlRegistry sqlRegistry) {
this.sqlRegistry = sqlRegistry;
}
public void setUnmarshaller(Unmarshaller unmarshaller) {
this.oxmSqlReader.setUnmarshaller(unmarshaller);
// Service의 프로퍼티로 DI 받은 것을 그대로 내부 클래스인 Reader로 옮겨줍니다.
}
public void setSqlmap(Resource sqlmap) {
this.oxmSqlReader.setSqlmap(sqlmap);
// 마찬가지로 리더로 전달합니다.
}
private class OxmSqlReader implements SqlReader {
private Unmarshaller unmarshaller;
private Resource sqlmap = new ClassPathResource("sqlmap.xml", UserDao.class);
public void setUnmarshaller(Unmarshaller unmarshaller) {
this.unmarshaller = unmarshaller;
// 전달받은 언마샬러 입니다.
}
...
}
}
final로 선언된 Reader를 사용하므로 DI하거나 변경할 수 없습니다. 하나의 클래스로 만들어 두기 때문에 빈의 설정이 최적화 됩니다. OXM을 적용하는 경우 외부에서 DI 해줄게 많기 떄문에 SqlReader를 단순한 디폴트 오브젝트 방식으로 제공할수는 없습니다.
OxmSqlReader는 스스로 빈으로 등록될 수 없습니다. 자신을 만드는 클래스의 프로퍼티를 통해 간접적으로 DI받아야 합니다.
이 방법은 OxmSqlReader의 경우 두 개의 프로퍼티를 DI해줘야 하기 떄문에, 어느 수정자 메소드에서 오브젝트를 생성해야 할지 모릅니다. 스프링이 어떤 순서로 프로퍼티를 설정해줄지 알 수 없기 떄문입니다. 그래서 미리 오브젝트를 만들어두고(스태틱, 코드에서는 final 필드) 각 수정자 메소드에서 DI받은 값을 넘겨주게 합니다.
sqlmap은 OxmSqlReader의 디폴트 값을 사용할 것이고, 언마샬러는 스프링의 빈에의해 제공됩니다.
이렇게 최적화해서 빈설정은 단 두개면 됩니다.
<bean id="sqlService" class="OxmSqlServcie경로">
<property name="unmarshaller" ref="unmarshaller" />
<bean id="unmarshaller" class="Jaxb2...">
<property name="contextPath" value="springbook.user.sqlservice.jaxb" />
OxmSqlServie는 OXM에 최적화된 빈 클래스를 만들기 위한 틀입니다. 그런데 BaseSqlSevice와 loadSql()과 getSql()이 겹치게 됩니다. 이를 해결하기 위해서 메소드 추출방식을 적용하기엔 애매하고, 프록시방식을 써서 OxmSqlService를 프록시로, SqlService의 기능 구현을 BaseSqlService로 위임하게 할 수도 있지만, 이 경우도 두 개의 빈을 등록해야되서 불편합니다.
Reader를 Serivce안에 고정시킨 것처럼, OxmlSqlService 내부에 BaseSqlService를 두고 위임하면 중복된 코드를 줄일 수 있습니다. 관련된 로직도 BaseSqlService만 수정하면 됩니다.
public class OxmSqlService implements SqlService {
private final BaseSqlService baseSqlService = new BaseSqlService();
...
@PostConstruct
public void loadSql() {
this.baseSqlService.setSqlReader(this.oxmSqlReader);
this.baseSqlService.setSqlRegistry(this.sqlRegistry);
this.baseSqlService.loadSql();
// 위임 합니다.
}
public String getSql(String key) throws SqlRetrievalFailureException {
return this.baseSqlService.getSql(key);
}
3-3. 리소스 추상화
지금까지 만든 OxmSqlReader나 XmlSqlReader에는 같은 클래스 패스에 존재하는 파일로만 제한되는 단점이 있습니다. 특정 폴더에서 읽어와야하거나, 웹상에서 읽어와야 하거나, 서블릿 컨텍스트의 상대적 폴더에서 읽어야할 수도 있습니다. 아쉽게도 스프링은 다양한 위치에 존재하는 리소스에 대한 서비스 추상화를 제공하지 않습니다.
대신 스프링은 일관성 없는 리소스 접근 API를 추상화해서 Resource라는 인터페이스를 제공합니다. 애플리케이션 컨텍스트가 xml설정 정보를 읽어오는 것을 포함해서 스프링의 모든 API가 외부 리소스를 읽어올 때 이 Resource 추상화를 이용합니다. 이 Resource는 스프링에서 빈이 아니라 값으로 취급합니다. 그래서 추상화를 적용하는 방법이 문제입니다. 값으로 등록되니 property태그의 value값 이용해 문자열 값을 넣을 수 밖에 없습니다.
그래서 스프링에서는 URL클래스와 유사하게 접두어를 이용해 Resource 오브젝트를 선언하는 방법이 있습니다. 문자열에 리소스의 종류와 위치가 표현됩니다. 이렇게 정의된 리소스를 실제 Resource 타입 오브젝트로 변환해주는 ResourceLoader 인터페이스를 제공합니다. 이 ResourceLoader도 리소스에 따라 구현이 다양합니다. 접두어로는 file:, classpath:, http: 등이 있습니다. 접두어가 안붙을 경우 구현에 따라 달라집니다.
앞에서 말한 것 처럼 애플리케이션 컨텍스트도 ResourceLoader의 일종입니다. 모든 빈으로 등록가능한 클래스에, 파일을 지정하는 프로퍼티가 있다면 모두 Resource타입이고, 애플리케이션 컨텍스트가 문자열을 이용해 오브젝트로 변환해서 주입합니다. Resource타입은 getInputStream()을 이용해 스트림으로 가져올 수 있습니다.
이제, Resource인터페이스를 이용해 xml을 가져오도록 변경합니다.
public class OxSqlService implements SqlService{
...
public void setSqlamp(Resource sqlmap){
// 기존에 파라미터가 String 타입이었던 sqlmap을 Resource타입으로 바꿉니다.
this.oxmSqlReader.setSqlmap(sqlmap);
}
...
private class OxmSqlReader implements SqlReader{
private Resource sqlamp = new ClassPathResource("sqlmap.xml", UserDao.class);
// String 타입이 아닌 ClassPathResource를 이용합니다.
public void setSqlmap(Resource sqlmap){
this.sqlmap = sqlmap;
}
public void read(SqlRegistry sqlRegistry){
try{
Source source = new StreamSource(sqlmap.getInputStream());
// 리소스 종류에 상관없이 스트림으로 가져올 수 있습니다.
..
}
...
}
}
}
// xml설정
<bean id="sqlService" ...>
<property name="sqlmap" value="classpath:springbook/user/dao/sqlmap.xml" />
// 클래스 패스 루트로부터 절대 경로를 적습니다.
// 특정 위치에 있는 파일을 일거오려면 file:을 붙여서 시세틈 루트 디렉토리부터 절대경로를 사용합니다.
// http: 접두어를 쓰면 웹상의 리소스를 가져옵니다.
Resource 오브젝트가 생성되도 실제 리소스는 아니라는 점을 주의해야 합니다. 단지 리소스에 접근하는 추상화된 핸들러일 뿐입니다.
4. 인터페이스 상속을 통한 안전한 기능확장
지금까지만든 SqlService 구현 클래스들은 SQL정보를 리소스로부터 읽어오면 메모리에 두고 그대로 사용합니다. 이를 실시간으로 변경하는 기능이 없습니다. 원칙적으로 이는 권장되진 않지만 필요할 상황이 있습니다. 어떻게 접근해야하는지 살펴봅니다.
4-1. DI와 기능의 확장
DI의 가치를 누리기는 쉬워보이지만 절대 쉽지않습니다. DI를 제대로 적용하려면 DI를 의식하면서 설계해야 합니다. DI를 적용하려면 커다란 오브젝트 하나만 존재해서는 안 되고, 최소한 두 개 이상의 의존관계를 가지고 협력해서 일하는 오브젝트가 필요합니다. 그래서 책임에 따라 오브젝트를 인터페이스로 분리해야 합니다. 그리고 항상 의존 오브젝트는 자유로운 확장이 보장되야 합니다. DI란 결국 미래를 설계하는 것 입니다.
4-2. 인터페이스의 상속
인터페이스를 여러 개 만들어서 구분하는 이유중 하나는 다른 종류의 클라이언트가 등장하기 때문입니다. 인터페이스 분리 원칙이 주는 장점은 모든 클라이언트가 관심외의 변경이 필요할 때 자신의 관심에 따른 접근 방식을 간섭 없이 유지할 수 있다는 점입니다.(오브젝트의 변경에 영향을 받지 않습니다.) BaseSqlService를 보면, MySqlRegistry의 구현 내용 변경을 통해 자신의 수정 없이 SQL등록기능이 확장 됐습니다. 다른 클라이언트에서 원한다면 MySqlRegistry를 더 확장한 클래스를 사용할 수 도 있습니다. 혹은 구현 인터페이스인 SqlRegistry를 확장한 새 인터페이스를 만들고 기능을 확장할 수 도 있습니다. 이런 경우에도 BaseSqlService의 코드는 프로퍼티타입이 SqlRegistry로 선언되 있기 때문에 기존 기능인 조회만 필요로 하기에 변할 필요가 없습니다.
결국 DI와 객체지향 설계는 밀접한 관계를 갖습니다.
<bean id="sqlService" class="basesql...">
<property name="sqlRegistry" ref="sqlRegistry">
<bean id="sqlAdminService" class="sqladmin...">
<property name="updateableSqlRegistry" ref="sqlRegistry">
<bean id="sqlRegistry" class="MyUpdateableSql...">
// MyUpdateSqlRegistry가 기존 SqlRegistry를 상속해 수정기능을 추가한 인터페이스를 구현한 클래스인 경우,
// property name으로 각자 다른 타입을 요구하지만, 각각 다른 인터페이스를 통해 같은 클래스를 주입하게 됩니다.
public inteface UpdateableSqlService extneds SqlRegistry{...}
5. DI를 이용해 다양한 구현 방법 적용하기
실시간으로 변경하는 작업은 동시성(synchronized) 문제를 가장 먼저 고려해야 합니다. 읽기전용으로 동작하는 SqlRegistry의 방식에서는 여러 스레드가 함께 접근할 때 발생하는 동시성 문제가 없습니다. 하지만 수정은 다릅니다.
5-1. ConcurrentHashMap을 이용한 수정 가능 SQL 레지스트리
지금까지 디폴트로 써온 HashMapRegistry는 HashMap를 사용합니다. 하지만 HashMap은 멀티스레드 환경에서 안전하게 조작하려면 Collections.synchronizedMap()을 이용해서 외부에서 동기화 해줘야 합니다. 하지만 이럴경우 성능에 문제가 생깁니다. 그래서 동기화된 해시 데이터 조작에 최적화된 ConcurrentHashMap을 사용하는 방법이 권장됩니다.
ConcurretHashMap은 데이터 조작 시 전체 데이터에 락을 걸지 않고, 조회시는 아예 락을 사용하지 않습니다. ConcurrentHashMap을 이용해 UpdatableSqlRegistry를 구현하기전에 테스트로 먼저 검증해봅니다. 검증을 위해서 기존 UserDao를 사용할 수 없습니다. 별도의 단위 테스트를 만들어서 SQL의 등록과 조회, 수정이 일어나는지 확인해봅니다.
public class ConcurrentHashMapSqlRegistryTest {
UpdatableSqlRegistry sqlRegistry;
@Before
public void setUp() {
sqlRegistry = new ConcurrentHashMapSqlRegistry();
sqlRegistry.registerSql("KEY1", "SQL1");
sqlRegistry.registerSql("KEY2", "SQL2");
sqlRegistry.registerSql("KEY3", "SQL3");
}
// 픽스처 입니다.
@Test
public void find() {
checkFindResult("SQL1", "SQL2", "SQL3");
}
private void checkFindResult(String expected1, String expected2, String expected3) {
// 검증을 위한 메소드입니다. 반복적으로 사용될 것이므로 메소드로 묶습니다.
assertThat(sqlRegistry.findSql("KEY1"), is(expected1));
assertThat(sqlRegistry.findSql("KEY2"), is(expected2));
assertThat(sqlRegistry.findSql("KEY3"), is(expected3));
}
@Test(expected= SqlNotFoundException.class)
public void unknownKey() {
sqlRegistry.findSql("SQL9999!@#$");
// 예외 상황에 대한 테스트도 항상 고려해야합니다.
}
@Test
public void updateSingle() {
sqlRegistry.updateSql("KEY2", "Modified2");
// 하나의 SQL을 변경하는 기능 테스트입니다.
checkFindResult("SQL1", "Modified2", "SQL3");
// 나머지 SQL은 그대로인지 확인합니다.
}
@Test
public void updateMulti() {
Map<String, String> sqlmap = new HashMap<String, String>();
sqlmap.put("KEY1", "Modified1");
sqlmap.put("KEY3", "Modified3");
sqlRegistry.updateSql(sqlmap);
// 한번에 여러개를 수정합니다.
checkFindResult("Modified1", "SQL2", "Modified3");
}
@Test(expected=SqlUpdateFailureException.class)
public void updateWithNotExistingKey() {
sqlRegistry.updateSql("SQL9999!@#$", "Modified2");
// 존재하지 않는 키의 SQL을 변경하려는 예외입니다.
}
}
SqlService나 SqlRegistry의 구현 클래스 등은 수동으로 손쉽게 테스트 하기 힘듭니다. 이런 코드는 테스트를 철저하게 만들어서 구현 방식이 변경될 때마다 테스트를 실행해서 기능에 영향을 주는지 확인해야 합니다.
이어 성공하는 코드를 만들기위해 ConcurrentHashMap을 사용도록 기존 HashMapMyRegistry클래스를 변경합니다.
public class ConcurrentHashMapSqlRegistry implements UpdatableSqlRegistry {
private Map<String, String> sqlMap = new ConcurrentHashMap<String, String>();
// HashMap에서 Concurrent..를 사용하도록 변경합니다.
public String findSql(String key) throws SqlNotFoundException {
String sql = sqlMap.get(key);
if (sql == null) throw new SqlNotFoundException(key + "를 이용해서 SQL을 찾을 수 없습니다.");
else return sql;
}
public void registerSql(String key, String sql) { sqlMap.put(key, sql); }
public void updateSql(String key, String sql) throws SqlUpdateFailureException {
// 기존 SqlRegistry에서 확장된 메소드
if (sqlMap.get(key) == null) {
throw new SqlUpdateFailureException(key + "에 해당하는 SQL을 찾을 수 없습니다.");
}
sqlMap.put(key, sql);
}
public void updateSql(Map<String, String> sqlmap) throws SqlUpdateFailureException {
// 기존 SqlRegistry에서 확장된 메소드
for(Map.Entry<String, String> entry : sqlmap.entrySet()) {
updateSql(entry.getKey(), entry.getValue());
}
}
}
// 빈설정도 잊지말고 바꿔줍니다.
아쉽지만 동시성에 대한 부분은 테스트하기 어려우므로 넘어갑니다.
5-2. 내장형 데이터베이스를 이용한 SQL 레지스트리 만들기
이번엔 애플리케이션에 내장되서 애플리케이션과 함께 시작되고 종료되는 내장형 DB를 이용해 SQLRegistry를 만들어 보겠습니다.
인덱스를 이용한 최적화된 검색을 지원하고 동시에 복잡한 많은 요청을 처리하면서 안정적인 변경 작업이 가능한 기술이 바로 데이터베이스 입니다.
최적화된 락킹, 격리수준, 트랜잭션을 적용할 수도 있습니다.
스프링에서 사용하는 내장형 DB는 Derby, HSQL, H2를 꼽을 수 있습니다. JDBC접근 방식이라고 해서 기존의 DataSource와 DAO를 사용하는 모델을 그대로 사용하는 것은 좋지 않습니다.
내장형 DB는 일종의 서비스 추상화 기능으로 제공되지만 별도의 인터페이스를 갖진 않습니다. 내장형 DB는 애플리케이션 안에서 직접 종료를 요청해야 하기에, DataSource 인터페이스를 상속한 EmbeddedDatabase 인터페이스를 제공합니다.(shutdown메소드가 추가됌.)
아래의 코드로 학습해봅니다.
// schma.sql 이라는 이름으로 저장합니다.
// 키와 SQL문장을 저장할 필드를 가진 SQLMAP 테이블입니다.
CREATE TABLE SQLMAP(
KEY_ VARCHAR(100) PRIMARY KEY,
SQL_ VARCHAR(100) NOT NULL
);
// 초기 데이터를 위한 SQL data.sql을 준비합니다.
INSERT INTO SQLMAP(KEY_, SQL_) values('KEY1', 'SQL1');
INSERT INTO SQLMAP(KEY_, SQL_) values('KEY2', 'SQL2');
// 내장형 DB 테스트
public class EmbeddedDbTest {
EmbeddedDatabase db;
SimpleJdbcTemplate template; // JdbcTemplate를 확장한 템플릿
@Before
public void setUp() {
db = new EmbeddedDatabaseBuilder() //빌더
.setType(HSQL) // 사용할 DB 종류
.addScript("classpath:/springbook/learningtest/spring/embeddeddb/schema.sql") // 테이블 생성
.addScript("classpath:/springbook/learningtest/spring/embeddeddb/data.sql") // 데이터 초기화
.build();
template = new SimpleJdbcTemplate(db);
}
@After
public void tearDown() {
db.shutdown(); // 테스트 후 종료합니다.
}
@Test
public void initData() {
// 검증하는 메소드입니다.
assertThat(template.queryForInt("select count(*) from sqlmap"), is(2));
List<Map<String,Object>> list = template.queryForList("select * from sqlmap order by key_");
assertThat((String)list.get(0).get("key_"), is("KEY1"));
assertThat((String)list.get(0).get("sql_"), is("SQL1"));
assertThat((String)list.get(1).get("key_"), is("KEY2"));
assertThat((String)list.get(1).get("sql_"), is("SQL2"));
}
@Test
public void insert() {
// 새로운 데이터를 추가하고 확인합니다.
template.update("insert into sqlmap(key_, sql_) values(?,?)", "KEY3", "SQL3");
assertThat(template.queryForInt("select count(*) from sqlmap"), is(3));
}
}
사용방법이 복잡해보입니다. 사실 스프링은 팩토리 빈을 만들어 주는 작업을 대신 해주는 전용 태그가 jdbc 스키마에 정의되어 있습니다.
<jdbc:embedded-database id="embeddedDatabase" type="HSQL">
<jdbc:script location="classpath:schma.sql" />
이렇게 설정하면 embeddedDataBase 빈이 등록되면 타입은 EmbeddedDatabase 입니다. 이제 UpdatabaleSqlRegistry를 내장형 DB를 DI 받도록 수정합니다.
public class EmbeddedDbSqlRegistry implements UpdatableSqlRegistry {
SimpleJdbcTemplate jdbc;
public void setDataSource(DataSource dataSource) {
jdbc = new SimpleJdbcTemplate(dataSource);
// DI 받습니다. EmbeddedDatabase 타입이 DataSource를 상속받았기에 DI가 가능합니다.
}
public void registerSql(String key, String sql) {
jdbc.update("insert into sqlmap(key_, sql_) values(?,?)", key, sql);
}
public String findSql(String key) throws SqlNotFoundException {
try {
return jdbc.queryForObject("select sql_ from sqlmap where key_ = ?", String.class, key);
}
catch(EmptyResultDataAccessException e) {
// 쿼리의 결과가 없을경우
throw new SqlNotFoundException(key + "에 해당하는 SQL을 찾을 수 없습니다.", e);
}
}
public void updateSql(String key, String sql) throws SqlUpdateFailureException {
int affected = jdbc.update("update sqlmap set sql_ = ? where key_ = ?" , sql, key);
// SQL 실행 결과로 영향받은 레코드의 개수를 리턴합니다.
if (affected == 0) {
throw new SqlUpdateFailureException(key + "에 해당하는 SQL을 찾을 수 없습니다.");
}
}
public void updateSql(Map<String, String> sqlmap) throws SqlUpdateFailureException {
for(Map.Entry<String, String> entry : sqlmap.entrySet()) {
updateSql(entry.getKey(), entry.getValue());
}
}
}
우리는 이제 EmbeddedDbSqlRegistry에 대한 테스트 만들어서 검증해야 합니다. 생각해야 할것은 기존의 ConcurrentHashMapSqlRegistry와 EmbeddedDbSqlRegistry 둘다 UpdatableSqlRegisty를 구현하기에 테스트에서 내용이 중복될 가능성이 높습니다. 그렇다면 기존의 테스트 코드를 우리가 만들 테스트 코드가 상속을 통해 공유하는 방법을 찾으면 좋습니다. 그리고 Concurrent…는 의존 오브젝트가 아예 없고, Embedded…의 경우는 내장DB 빈을 의존하지만 이를 mock오브젝트로 대체하긴 어렵습니다. 따라서 DAO는 DB까지 연동하는 테스트를 하는 편이 좋습니다.
public class ConcurrentHashMapSqlRegstryTest{
UpdatableSqlRegistry sqlRegistry;
@Befor
public void setUp(){
sqlRegistry = new ConcurrentHashMapSqlRegistry();
// 테스트에서 사용할 픽스처를 인터페이스로 정의해 뒀습니다.
// 이 부분만 ConcurrentHashMap...라는 특정 클래스에 의존하고 있습니다.
// 이 부분만 분리한다면 나머지 테스트 코드는 공유가 가능해집니다.
}
...
}
의존 오브젝트가 들어나는 부분을 추상 메소드로 전환하고 클래스자체를 추상 클래스로 바꿉니다.
public abstract class AbstractUpdatableSqlRegistryTest {
UpdatableSqlRegistry sqlRegistry;
@Before
public void setUp() {
sqlRegistry = createUpdatableSqlRegistry();
// 의존 오브젝트가 들어나는 부분을 추상 메소드로 분리합니다.
sqlRegistry.registerSql("KEY1", "SQL1");
sqlRegistry.registerSql("KEY2", "SQL2");
sqlRegistry.registerSql("KEY3", "SQL3");
}
abstract protected UpdatableSqlRegistry createUpdatableSqlRegistry();
// 서브 클래스에서 구현할 테스트 픽스처를 담을 오브젝트를 생성하는 부분입니다.
@Test
public void find() {
checkFind("SQL1", "SQL2", "SQL3");
}
@Test(expected=SqlNotFoundException.class)
public void unknownKey() {
sqlRegistry.findSql("SQL9999!@#$");
}
protected void checkFind(String expected1, String expected2, String expected3) {
// 서브 클래스에서 접근이 가능하도록 protected로 선언합니다.
assertThat(sqlRegistry.findSql("KEY1"), is(expected1));
assertThat(sqlRegistry.findSql("KEY2"), is(expected2));
assertThat(sqlRegistry.findSql("KEY3"), is(expected3));
}
@Test
public void updateSingle() {
...
}
// 이제 추상 메소드를 구현합니다.
public class ConcurrentHashMapSqlRegistryTest extneds AbstractUpdatableSqlRegistryTest{
protected UpdatableSqlRegistry createUpdatableSqlRegistry(){
return new ConcurrentHashMapSqlRegistry();
}
}
//다음은 우리가 구현하려 했던 테스트 입니다.
public class EmbeddedDbSqlRegistryTest extends AbstractUpdatableSqlRegistryTest {
EmbeddedDatabase db;
@Override
protected UpdatableSqlRegistry createUpdatableSqlRegistry() {
// DI해줄 내장 DB를 빌더를 이용해 생성합니다.
db = new EmbeddedDatabaseBuilder()
.setType(HSQL)
.addScript("classpath:springbook/user/sqlservice/updatable/sqlRegistrySchema.sql")
.build();
EmbeddedDbSqlRegistry embeddedDbSqlRegistry = new EmbeddedDbSqlRegistry();
embeddedDbSqlRegistry.setDataSource(db);
return embeddedDbSqlRegistry;
}
@After
public void tearDown() {
db.shutdown();
// 반드시 모든 테스트 마다 닫아주도록 합니다.
}
}
// xml 설정으로 sqlRegistry 빈의 클래스를 EmbeddedDbsqlRegistry로 변경하고, datasource 프로퍼티의 ref 값을 embeddedDatabase로 수정합니다.
5-3. 트랜잭션 적용
updateSql()는 단순히 SimplJdbcTemplate을 사용하 SQL을 실행하므로 트랜잭션이 적용되있지 않습니다. 기본적으로 HashMap과 같은 컬랙션은 트랜잭션 개념을 적용하기 어렵습니다. 한 개의 엘리먼트를 수정하는 것은 락킹을 이용해 안정성을 보장하지만, 여러 개의 엘리먼트를 트랜잭션 같이 원자성이 보장된 상태에서 변경하려면 복잡합니다. 반면에 내장형 DB를 사용하는 경우에는 상대적으로 쉽습니다. 트랜잭션을 적용할 때 트랜잭션 경계가 DAO 밖에있고 범위가 넓은 경우라면 AOP를 이용하면 편리합니다. 하지만 제한된 오브젝트에서 간단한 트랜잭션을 사용하는 경우 트랜잭션 추상화 API를 직접사용하는 것이 편리합니다. 우선 성공하기 위한 테스트 코드를 만들어봅니다.
public class EmbeddedDbSqlRegistryTest extends AbstractUpdatableSqlRegistryTest {
...
@Test
public void transactionalUpdate() {
checkFind("SQL1", "SQL2", "SQL3");
// 초기 상태를 확인합니다. 롤백 후의 상태는 처음과 동일하다는 것.
Map<String, String> sqlmap = new HashMap<String, String>();
sqlmap.put("KEY1", "Modified1");
sqlmap.put("KEY9999!@#$", "Modified9999");
// 이 키는 존재하지 않으므로 실패를 유도합니다.
try {
sqlRegistry.updateSql(sqlmap);
// 여기서 예외가 발생하지 않으면 실패입니다.
fail();
}
catch(SqlUpdateFailureException e) {}
checkFind("SQL1", "SQL2", "SQL3");
// 트랜잭션이 적용 됐다면 변경 이전상태로 돌아옵니다.
}
지금은 테스트 실패를 확인하는 것이 목적입니다. 이를 검증하기 위해서 트랜잭션 기능을 추가해봅니다. Jdbc를 처리하고 있으므로 스프링의 트랜잭션 추상화 서비스를 이용할 수 있습니다. 템플릿.콜백 패턴을 적용한 TransactionTemplate을 사용합니다. 보통 여러 개의 AOP를 통해 만들어지는 트랜잭션 프록시는 같은 트랜잭션 매니저를 공유해야 하기 때문에, 트랜잭션 매니저를 싱글톤 빈으로 등록해서 사용합니다. 하지만 EmbeddedDbSqlRegistry가 사용할 내장형 DB에 대한 트랜잭션 매니저는 공유할 필요가 없으므로, 내부에 만들어서 본인만 사용하게 하는것이 낫습니다. TransactionTemplate 은 멀티스레드 환경에서 공유해도 안전하도록 만들어져, 인스턴스 변수에 저장해두고 사용합니다.
public class EmbeddedDbSqlRegistry implements UpdatableSqlRegistry {
SimpleJdbcTemplate jdbc;
TransactionTemplate transactionTemplate;
// 공유가능한 트랜잭션 템플릿입니다.
public void setDataSource(DataSource dataSource) {
jdbc = new SimpleJdbcTemplate(dataSource);
transactionTemplate = new TransactionTemplate(
new DataSourceTransactionManager(dataSource));
transactionTemplate.setIsolationLevel(TransactionTemplate.ISOLATION_READ_COMMITTED);
// 격리 수준입니다. 낮은 격리수준 위험성을 피하려면 READ_COMMITTED격리수준을 사용합니다.
}
...
public void updateSql(String key, String sql) throws SqlUpdateFailureException {
int affected = jdbc.update("update sqlmap set sql_ = ? where key_ = ?" , sql, key);
if (affected == 0) {
throw new SqlUpdateFailureException(key + "에 해당하는 SQl을 찾을 수 없습니다.");
}
}
public void updateSql(final Map<String, String> sqlmap) throws SqlUpdateFailureException {
// 익명 내부 클래스로 만들어지는 콜백 오브젝트 안에서 사용되는 것이라 final로 선언합니다.
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
protected void doInTransactionWithoutResult(TransactionStatus status) {
for(Map.Entry<String, String> entry : sqlmap.entrySet()) {
updateSql(entry.getKey(), entry.getValue());
// udpate(String, String) 입니다.
}
// 템플릿이 만드는 트랜잭션 경계 안에서 동작할 코드(작업, 로직) = 콜백
// 콜백을 TrasactionTemplate의 execute()로 전달합니다.
// 클라이언트인 테스트에서 sqlmap을 전달해 이 메소드를 호출합니다.
}
});
}
}
낮은 격리수준 문제점 : 한 트랜잭션이 커밋하기 전의 작업 내용을 다른 트랜잭션이 읽을 위험이 있습니다. 작업 내용이 롤백 될 수도 있으므로 문제가 생깁니다.
6. 스프링 3.1의 DI
스프링이 제공하는 DI의 원리는 변하지 않았지만, 자바 언어에는 적지 않은 변화가 있었습니다. 이런 변화들이 DI프레임워크로서 스프링의 사용 방식에도 영향을 줬습니다.
- 애노테이션의 메타정보 활용
자바 코드의 메타정보를 이용한 프로그래밍 방식입니다. 자바 코드의 일부를 리플랙션 API등을 이용해 살펴보고 그에 따라 동작하는 기능이 많이 사용되고 있습니다. 실행되는 것이 목적이 아닌 다른 코드에 의해 데이터 취급을 받는 것입니다. 이런 방식의 절정은 애노테이션 입니다. 애노테이션은 옵션에 따라 컴파일된 클래스에 존재하거나 메모리에 로딩되기도 하지만, 자바 코드를 실행시키는데 참여하지는 못합니다. 값을 참조하거나 활용도 할 수 없습니다. 리플랙션 API를 이용해 애노테이션의 메타정보를 조회하고, 설정된 값을 가져와 참조하는 것이 전부였습니다. 그럼에도 애노테이션을 이용하는 프레임워크는 빠르게 증가했습니다.
그 이유는 핵심 로직을 담은 자바 코드와 이를 지원하는 프레임워크, 프레임워크가 참조하는 메타정보라는 세 가지로 구성된 방식에 잘 어울리기 때문입니다.
기존에 DAOFactory 클래스가 DI를 위해 참고하는 일종의 메타정보를 담고 있는 클래스로 보았다면, 자바 코드로 이 관계를 만들기 불편한 점이 있어서 xml 정보를 사용했습니다.
하지만 애노테이션이 등장하면서 상황이 달라졌습니다. 애노테이션은 xml과 달리 자바 코드에 나타나, 여러가지 정보를 직관적으로 얻을 수 있습니다. 물론 단점도 있습니다, xml은 손쉽게 편집이 가능하고 수정할 때 마다 빌드를 거칠 필요가 없지만, 애노테이션은 코드에 존재하므로 변경할 때마다 매번 클래스를 컴파일 해줘야 합니다.
스프링 3.1에서는 애토에션을 이용한 메타정보 작성 방식이 거의 모든 영역으로 확대돼서, xml없이도 애플리케이션을 작성할 수 있게 됐습니다.
즉, 스프링 3.1에 이르러서 애노테이션을 핵심 로직을 담은 코드와 DI 프레임워크, DI를 위한 메타데이터로서 자바 코드로 재구성 됐습니다.
- 정책과 관례를 이용한 프로그래밍
루비 언어를 기반으로 한 RoR 프레임워크의 영향을 받아 미리 정해진 규칭기나 관례를 이용해서 작성해야 할 메타정보의 양을 최소화 했습니다.
이제부터 애노테이션을 사용하도록 xml을 없에는 리팩토링을 해봅니다.
6-1. 자바 코드를 이용한 빈 설정
먼저 test-applicationContext.xml을 사용하는 테스트 컨텍스트 먼저 변경합니다. DI정보를 이용해 테스트 하는 UserDaoTest와 UserServiceTest만 신경쓰면 됩니다. xml대신 DI로 쓸 정보를 담을 클래스를 만듭니다.
Configuration애노테이션은 메타정보로 이용하겠다는 애노테이션 입니다.
@Configration
@ImportResource("/test-applicationContext.xml")
// 당장 xml을 지우면 에러가 나므로, ImportResource를 이용해 xml설정정보를 가져오게 합니다.
public class TestApplicationContext{
}
// 이후 UserDao와 UserServiceTest의 ContextConfiguration 애노테이션을 변경합니다.
@RunWith(...)
@ContextConfiguratio(classes=TestApplicationContext.class)
public class UserDaoTest{}
Configuration을 이용하면 PosrConstruct 애노테이션을 붙여 빈 후처리기를 등록하던 context:annotation-config 태그를 삭제해도 됩니다.
그 이유는 Configuration이 붙은 자바 클래스를 DI로 사용하면 컨테이너가 직접 빈 후처리기를 등록해줍니다.
다음은 bean들을 전환해야 합니다. 먼저 datasource의 빈을 메소드로 정의해 봅니다. Cofngiruation 애노테이션 클래스 안에서 Bean 애노테이션을 이용하면 메소드 이름으로 빈이 등록됩니다. 기존 bean태그의 내용들을 자바 코드로 수정합니다. 이때 코드를 이용하게 되면 bean 메소드들은 public으로 선언되야 합니다.
@Bean
public DataSource dataSource() {
// 리턴값은 의존 관계를 고려해 인터페이스인 DataSource로 합니다.
SimpleDriverDataSource ds = new SimpleDriverDataSource();
// 선언 타입은 setUrl 등을 위해 확장된 SimpleDriver..구현 클래스를 이용합니다.
ds.setDriverClass(Driver.class);
ds.setUrl("jdbc:mysql://localhost/springbook?characterEncoding=UTF-8");
ds.setUsername("spring");
ds.setPassword("book");
return ds;
}
// datasource를 주입받는 transactionManager 빈 입니다.
@Bean
public PlatformTransactionManager transactionManager() {
DataSourceTransactionManager tm = new DataSourceTransactionManager();
tm.setDataSource(dataSource());
return tm;
}
// UserServiceTest 클래스의 TestUserService는 private으로 선언되어 @Bean이 불가능합니다.
// public 으로 수정합니다.
@Autowired
SqlService sqlService;
// 밑에 설명 참조.
@Bean
public UserDao userDao() {
UserDaoJdbc dao = new UserDaoJdbc();
dao.setDataSource(dataSource());
dao.setSqlService(this.sqlService);
// sqlService 빈과 일치하는 메소드 이름이 없어서 오류가 나게 되지만
// sqlServic를 자바 코드로 변환하면 해결됩니다.
// 다만 그전에 autowired를 통해 xml 설정의 빈을 가져오면 해결됩니다.
// autowired 는 필드 타입으로 주입한다는 것에 주의합니다.
return dao;
}
@Bean
public UserService userService() {
UserServiceImpl service = new UserServiceImpl();
service.setUserDao(userDao());
service.setMailSender(mailSender());
return service;
}
@Bean
public UserService testUserService() {
TestUserService testService = new TestUserService();
testService.setUserDao(userDao());
testService.setMailSender(mailSender());
return testService;
}
@Bean
public MailSender mailSender() {
return new DummyMailSender();
}
// 네임스페이스를 사용한 embeddedDataBase 빈(내장DB)은 제외하고 등록합니다.
// @Resource
// EmbeddedDatabase embeddedDatabase;
// Resource 애노테이션은 필드 이름을 기준으로 가져옵니다.
// embedded...는 해당 애노테이션을 사용해서 xml설정에서 불러옵니다.
// Resource를 사용한 이유는 타입을 기준으로 하는 autowired에서 이미 datasource가 겹쳐버려 혼돈이 생깁니다.
// 메소드로 등록하고 싶다면 빌더를 이용합니다.
@Bean
public DataSource embeddedDatabase() {
return new EmbeddedDatabaseBuilder()
.setName("embeddedDatabase")
.setType(HSQL)
.addScript("classpath:springbook/user/sqlservice/updatable/sqlRegistrySchema.sql")
.build();
}
@Bean
public SqlService sqlService() {
OxmSqlService sqlService = new OxmSqlService();
sqlService.setUnmarshaller(unmarshaller());
sqlService.setSqlRegistry(sqlRegistry());
return sqlService;
}
@Bean
public SqlRegistry sqlRegistry() {
EmbeddedDbSqlRegistry sqlRegistry = new EmbeddedDbSqlRegistry();
sqlRegistry.setDataSource(embeddedDatabase());
return sqlRegistry;
}
@Bean
public Unmarshaller unmarshaller() {
Jaxb2Marshaller marshaller = new Jaxb2Marshaller();
marshaller.setContextPath("springbook.user.sqlservice.jaxb");
return marshaller;
}
이제 남은 태그는 AOP기능을 지원하는 tx:annotation-driven입니다. 해당 코드는 EnableTransactionManagement 애노테이션을 클래스에 추가해 주면 됩니다.
6-2. 빈 스캐닝과 자동와이어링
지금까지 Autowired 애노테이션은 메타정보용 클래스에서 빈을 클래스의 맴버 필드로 주입받기 위해 사용했습니다. 다른 경우로도 사용할 수 있습니다.
현재 UserDaoJdbc에서는 dataSource와 sqlService 두 개의 빈에 수정제 메소드에 의해 의존합니다. 이것을 수정자 메소드나 필드에 자동와이어링을 붙여 제거할 수 있습니다.
// Configurateion 클래스의 userDao 빈 메소드 정의
public UserDao userDao{
... new UseDaoJdbc
dao.setDataSource(dataSource());
dao.setSqlService(this.sqlService);
return dao;
]
// 이 코드를 자동와이어링을 이용해 제거할 수 있습니다.
public class UserDaoJdbc implements UserDao{
@Autowired
// 메소드의 파라미터 타입을 보고주입 가능 한 빈을 찾습니다.
public void setDataSource(DataSoruce dataSource){
this.jdbcTemplate = new JdbcTemplate(dataSource);
// 필드에 저장하는 것이 아닌 jdbcTemplate에 주입해야 하므로 수정자 메소드에 자동 와이어링합니다.
}
@Autowired
private SqlService sqlService;
// 리플랙션을 이용하므로 private으로 선언해도 주입이 가능합니다.
// public void setSqlService(SqlService sqlService){
// this.sqlService = sqlService;
// }
//생략 가능합니다.
}
// 이제 UserDao 빈 메소드가 깔끔해집니다.
// autowired 하던 sqlService도 지웁니다.
public UserDao userdao{
return new UserDaoJdbc;
}
수정자 메소드에 autowired가 있다면 파라미터 타입을 보고 주입 가능한 DataSource타입 빈을 모두 찾습니다. 두개 이상 나오면, 프로퍼티와 동일한 이름의 빈이있는지 찾습니다. 해당 메소드에는 dataSource이고, dataSource빈과 embeddedDataBase 빈 중에 dataSource빈을 주입합니다.
직접 수동으로 DI를 해줘야 하는 경우(단위 테스트 같은)에는 수정자 메소드를 생략할 수 없습니다.
이번에는 아예 빈 메소드인 useDao()를 삭제합니다. Component 애노테이션을 이용합니다. 해당 애노테이션이 등록된 클래스를 찾아서 빈으로 등록합니다. 프로잭트 내의 모든 클래스패스를 다 찾는 것은 부담되므로, 빈 스캔 기능을 사용하겠다는 기준 클래스에 애노테이션 ComponentSacn이 필요합니다.
...
@ComponentScan(absePackages="springbokk.user")
// 기준 패키지는 여러개 넣어도 됩니다.
public class TestApplicationContext{
@Autowired
Userdao userDao;
// userdao 빈 메소드를 삭제하고 추가합니다.
}
@Component
// 자동으로 빈으로 추가합니다. 클래스의 이름을 빈 id로 사용합니다.
// 빈이름을 지정하려면 ("빈이름")을 추가합니다.
public class UserDaoJdbc implements UserDao{}
// component의 정의
public @interface Component{}
Component를 이용하면 프로퍼티 설정을 지정하기 힘듭니다. 그래서 모두 Autowired로 의존관계를 정의했습니다. 지금은 userDao타입의 빈이 1개이므로 모든 의존대상에 주입됩니다.
빈 자동등록은 Component애노테이션을 메타 애노테이션으로 갖고 있는 애노테이셔노 사용할 수 있습니다.
애노테이션은 interface 애노테이션을 이용해 정의합니다. 여러 개의 애노테이션에 공통적인 속성을 부여하려면 메타 애노테이션을 이용합니다. 만약 애노테잉션이 빈 스캔을 통해 자동등록하고, AOP 포인트컷으로 지정할 수 있도록 구분이 필요하다면 새로 정의한 애노테이션이 필요합니다.
@Component
public @interface SnsConnector{}
위와 같이 애노테이션을 정의할 수 있습니다. SnsConnector라는 애노테이션을 등록하면 자동 빈 등록 대상이 됩니다. 애노테이션은 AOP에서 포인트컷을 작성할 때 처럼 부가적인 용도의 마커로도 사용할 수 있습니다. 스프링은 DAO기능을 제공하는 클래스에 대해선 Component대신 Repository 애노테이션을 권장합니다. UserDaoJdbc는 Component 대신 Repository 애노테이션을 사용하도록 수정합니다.
이제 UserServiceImpl 클래스를 자동 빈 등록으로 변경하고, 프로퍼티들도 Autowrired로 수정합니다. 그런데 오류가 생깁니다. UserService 타입의 빈이 하나여야 하는데 두 개가 발견됐다는 오류입니다. UserServiceTest내부 클래스 testUserService라는 UserService타입 빈이 하나 더 있습니다. autowired가 결정을 못해 문제가 된 것입니다.
이 두가지 빈을 사용하는 UserServiceTest는 아래와 같이 수정합니다.
@Autowired UserService userService;
@Autowired UserService testUserService;
이 오류가 발생한 이유는 UserServiceImpl을 Component애노테이션을 붙이면서 빈 id가 userServiceImpl이 됐기 때문입니다. 따라서 빈 id를 수동으로 설정해줍니다. 추가적으로 스프링은 비즈니스 로직을 담고 있는 서비스 계층의 빈은 Service애노테이션을 사용하도록 권장합니다.
@Service("userService")
public class UserServiceImpl implements UserSerivce{}
testUserService빈과, mailSender빈은 우선 빈 메소드로 두도록합니다. dataSource와 transactionManager 빈은 스프링이 제공하는 클래스라 자동등록 빈 애노테이션을 적용할 방법이 없습니다.
6-3. 컨텍스트 분리와 Import 애노테이션
지금의 DI정보는 테스트를 위한 DI 정보와 바르게 동작하는데 필요한 DI 정보가 섞여있습니다. 분리하는 방법은 간단합니다. DI 설정 클래스를 추가하는 것입니다. 기존의 TestAppli..클래스는 AppContext로 변경합니다. 그리고 TestAppContext클래스를 만들어 테스트용 DI정보를 분리시킵니다.
자동 빈 등록을 적용한 userDao와 userService빈은 운영과 테스트 모두 필요합니다. DI정보로 등록된 DB연결, 트랜잭션 관리, SQL 서비스도 항상 필요합니다. 반면에 testUserService빈과 mailSender(더미mailSender) 빈은 테스트 에서만 필요합니다.
@Configuration
publc class TestAppConetext{
@Autowired
UserDao userDao;
// Repository을 적용해서 가져올 수 있습니다.
@Bean
public UserService testUserService(){...// setUserDao, setMailSender}
// UserServiceImpl을 상속했으므로 userDao프로퍼티는 자동와이어링 적용 대상입니다.
// 수정자 메소드로 userDao와 mailSender를 제거해도 됩니다.
// return new TestUserService();
@Bean
public MailSneder mailSender(){
return new DummyMailSender();
}
}
testUserService 빈은 autowired을 이용하여 빈들을 DI 받도록 간단하게 수정할 수 있습니다. 아예 Component(해당 애노테이션이 붙은 클래스를 찾아서 빈으로 등록)를 부여서 scan을 이용해 자동 등록이 되게 할 수도 있지만, 권장하진 않습니다.
스캔은 기준 패키지를 지정해서 클래스를 찾으므로, 운영과 테스트용으로 클래스를 분리시켜 만들었다면 스캔 위치도 분리시켜야 합니다. 하지만 지금은 UserDaoServiceImpl과 UserServiceTest 등이 같은 패키지 아래 존재하므로 기준 위치를 정하기 어렵습니다. 또 테스트용으로 만든 빈은 설정정보에 내용이 드러나는게 좋습니다.
이 테스트용 빈이 어떻게 구성된 것인지 파악하기가 좋기 때문입니다. 이제 테스트코드에 넣은 DI정보용 클래스도 수정해야 합니다.
@RunWith...
@ContextConfiguration(classes={TestAppContext.class, AppContext.class})
public class UserDaoTest{}
// DI설정 정보를 테스트용 운영용 둘다 필요하므로 classes에 적용할 설정 클래스를 나열합니다.
이제 AppContext에는 운영용 빈만 남게되었지만 여타 빈 설정과 구분되는 SQL 서비스용 빈이 남아있습니다. SQL서비스는 그 자체로 독립적인 모듈처럼 취급하는게 나아 보입니다.
SQL서비스는 다른 애플리케이션에서도 사용될 수 있기 떄문입니다. userDao 구현 빈들은 SQlService타입의 빈을 DI 받을 수 있기만 하면 됩니다. SqlService 구현 빈들은 애플리케이션을 구성하는 빈과 달리 독립적으로 개발될 가능성이 높습니다. 분리하는 방법은 Configuration 클래스를 하나 더 만들면 됩니다.
@Configuration
public class SqlServiceContext{
@Bean
public SqlService sqlService(){}
@Bean
public SqlRegistry ...
@Bean
public Unmarshaller ...
@Bean
public DataSource embeddedDataBase....
}
이제 빈 설정을 담은 클래스가 세 개가 됐습니다. classes로 SqlServiceContext를 추가해도 좋지만 다른 방법이 있습니다. 테스트용 빈과 다르게 SQL서비스 빈은 운영 중에 반드시 필요한 정보 입니다. 그래서 AppContext와 긴밀하게 연결해주는게 좋습니다. 전에 XML설정정보는 ImportResource 애노테이션을 이용해 따로 가져온 것과 같은 방법으로 적용할 수 있습니다.
AppContext가 메인 설정정보가되고, SqlServiceContext는 AppContext에 포함되는 보조 설정정보로 사용하는 것입니다. 메인 설정정보에 Import 애노테이션을 이용합니다.
@Configuration
@EnableTransactionManageMent // 트랜잭션 설정
@ComponentScan(basePackages="springbook.user")
@Import(sqlServiceContext.class) // 해당 설정정보가 함께 적용됩니다.
public class AppContext{}
6-4. 프로파일
이제 운영에서 필요한 설정정보는 AppContext하나로 충분하지만, 메일 서비스 빈은 테스트용 더미빈만 존재해 운영시에 사용될 MailSender 타입 빈 설정을 넣어줘야 합니다.
@Bean
public MailSender mailSender(){
JavaMailSenderImpl mailSender = new JavaMailSenderImpl();
// 스프링이 제공하는 클래스입니다.
mailSender.setHost("mail.mycompany.com");
return mailSender;
}
문제는 같은 타입이면서 아이디도 같은 mailSender 빈이 두개가 존재해 운영시, 테스트시에서 먼저 발견된 빈을 사용하는 문제가 생깁니다.(classes에 등록된 뒤에서부터 순서로 먼저 발견된 빈을 사용합니다.) 이렇게 양쪽에 필요하면서 내용은 달라야하는 경우 빈 설정 작성이 곤란해집니다. mailSender빈은 autowired를 통해 주입되기 때문에 빈 아이디를 다르게 설정하는 것으로도 해결 할 수 없습니다. 이럴 경우엔 우선 또 설정정보 클래스를 만들어서 운영용 mailSender빈을 새로운 설정정보 클래스로 옮기고, 테스트시에는 TestAppContext, AppContext를 사용하고, 운영시에는 AppContext와 새로운 설정정조 클래스를 이용하는 방법으로 해결할 수 있습니다.
이렇게 번거롭게 클래스를 분리해서 조합하는 방법대신 스프링 3.1에서는 Profile애노테이션을 이용해 빈 구성이 달라지는 내용을 프로파일로 만들고 실행 시점에 어떤 프로파일의 빈 설정을 사용할지 지정하게 할 수 있습니다.
프로파일은 간단한 이름과 빈 설정으로 구성됩니다. 프로파일을 적용하면 환경에 따라 여러 빈 설정 조합을 쉽게 만들어낼 수 있습니다.
@Configuration
@Profile("test")
public class TestAppContext{}
이제 TEstAppCOntext는 test 프로파일의 빈 설정정보를 담은 클래스가 됐습니다. Appcontext나 SqlServiceContext 클래스에는 굳이 프로파일을 지정하지 않아도 됩니다. 프로파일을 지정하지 않으면 default프로파일로 취급해 항상 적용됩니다.
이 방법으로 ProductionAppContext(운영시 mailSender 빈 설정정보 클래스)는 production 프로파일을 적용합니다.
프로파일을 적용하면 메인 설정 클래스에서 모든 설정 클래스를 Import해도 됩니다.
...
@Import({SqlServiceContext.class, TestAppContext.class, ProductionAppCotnext.class})
public class AppContext{}
// 메인 설정 클래스가 모두 Import하니 userDao와 userSevice에서 ContextConfiguration에 TestAppContext를 빼도 됩니다.
프로파일을 설정했으니, 어떤 설정정보를 참조하는 클래스에서 ActiveProfiles 애노테이션으로 사용할 프로파일을 지정해줘야 합니다.
UserDaoTest나 UserServiceTest가 실행될 때 활성 프로파일로 test프로파일을 지정하면 됩니다. 운영시에는 production으로 지정합니다.
....
@ActiveProfiles("test")
@ContextConfiguration(classes=AppContext.class)
public class UserServiceTest{}
프로파일이 일종의 필터처럼 작동한다고 봐도 좋습니다. 정말 설정한 프로파일만 가져오는지 테스트하기 위해선 DefaultListableBeanFactory를 이용해 검증합니다. 스프링 컨테이너는 이 클래스를 이용해 빈을 관리합니다. 스프링은 친절하게도 이 클래스를 autowired로 빈으로 주입받을 수 있게 합니다.
DefaultListableBeanFactory는 BeanFactory를 구현한 클래스입니다. 참고로 스프링 컨테이너는 모두 BeanFactory를 구현하고 있습니다.
@Autowired
DefaultListableBeanFactory bf;
// UserServiceTest 클래스 입니다.
@Test
public void beans(){
for(String n: bf.getBeanDefinitionNames()){
System.out.println(n + "\t" + bf.getBean(n).getClass().getName());
// 테스트 컨텍스트에 등록된 빈 이름과 빈 클래스를 모두 얻습니다.(프로파일 설정에따른)
// 출력 결과로 수동으로 빈을 확인해봅니다.
}
}
만약 전체 구성을 살펴보기 위해 설정정보를 하나로 모아야할 필요가 있다면, 중첩 클래스를 이용하면 됩니다. 메인 설정정보인 AppContext에 Product..Context와 TestAppContext를 스태틱 클래스로 지정하고, Import애노테이션에서 SqlServiceContext만 남겨둡니다. Configuration이 붙은 내부 클래스는 스프링이 자동으로 메인 설정정보에 포함시켜주기에 Import에서 제거 할 수 있습니다.
6-5. 프로퍼티 소스
AppContext에는 아직 환경에 따라 달라지는 빈이 있습니다. dataSource 빈입니다. 환경에 따라 DB연결 정보를 다르게 넣어줘야 합니다. 이런 외부 서비스 연결에 필요한 정보는 자바 클래스보다는 XML이나 프로퍼티 파일 같은 텍스트 파일에 저장해두는게 낫습니다. 자바의 프로퍼티 파일 포맷을 이용하면 됩니다. 확장자는 properties이고, 키=값 형태로 프로퍼티를 정의합니다.
// database.properties 파일
// db.을 붙여 서비스 종류가 햇갈리지 않게 추가합니다.
db.driverClass=com.mysql.jdbc.Driver
db.url=jdbc:mysql://localhost/springbook?characterEncoding=UTF-8
db.username=spring
db.password=book
이제 AppContext의 dataSource() 빈 메소드가 프로퍼티 파일의 내용을 가져와 DB연결을 생성하도록 만들어 봅니다.
컨테이너가 프로퍼티 값을 가져오는 대상을 프로피터 소스라고 합니다. PropertySource애노테이션을 이용해 프로퍼티파일의 위치를 지정해줍니다.
이렇게 가져온 프로피터 값은 Environment 타입의 환경오브젝트에 저장됩니다. 환경 오브젝트는 빈처럼 autowired를 통해 주입받을 수 있습니다.
@Configuration
@EnableTransactionManagement
@ComponentScan(basePackages="springbook.user")
@Import(SqlServiceContext.class)
@PropertySource("/database.properties")
public class AppContext {
@Autowired Environment env;
// getProperty(키)로 프로퍼티 파일의 값 가져옵니다.
@Bean
public DataSource dataSource() {
SimpleDriverDataSource ds = new SimpleDriverDataSource();
try {
ds.setDriverClass((Class<? extends java.sql.Driver>)Class.forName(env.getProperty("db.driverClass")));
// Class프로퍼티는 Class 타입오브젝트를 넘겨야 합니다.
// Class.forName()의 도움으로 Class 타입으로 변환시키고 사용합니다.
}
catch(ClassNotFoundException e) {
throw new RuntimeException(e);
}
ds.setUrl(env.getProperty("db.url"));
ds.setUsername(env.getProperty("db.username"));
ds.setPassword(env.getProperty("db.password"));
return ds;
}
이제 DB연결 정보는 설정정보 클래스에서 분리됐습니다. DB정보가 변경된다고 해도 AppContext의 코드를 수정하고 다시 빌드할 필요가 없습니다.
지금까지 Autowired는 빈 오브젝트를 필드나 수정자메소드의 파라미터로 주입받을 때 사용했습니다. dataSource 빈의 프로퍼티는 빈 오브젝트가 아닌 값이므로 autowired를 이용할 수 없습니다. 대신 Value애노테이션을 이용하면 됩니다. Value를 이용하면 프로퍼티를 가져오기 위해 Environment타입 오브젝트를 DI받는게 아닌 값을 직접 DI받을 수 있습니다.
Value의 사용법은 여러가지가 있지만 치환자를 이용해 필드에 주입하는 방법을 사용합니다. 이를 위해선 PropertySourcesPlacholderConfigurer라는 빈을 정의해야 합니다.
이 빈은 빈 팩토리 후처리기로 사용되, Value와 치환자를 이용해 프로퍼티를 필드에 주입해 줍니다.
...
@PropertySource("/database.properties")
public class AppContext{
@Value("${db.driverClass}")
Class<? extneds Driver> driverClass; // 필드로 선언합니다.
...
// ${}를 치환자(placeholder)라고 합니다. xml에서도 사용 가능한데, 프로퍼티태그의 value값에 #{}를 넣으면
// 가져온 리소스의 실제 값으로 바꿔치기합니다.
// ${db.driverClass}는 프로퍼티 파일에서 가져온 실제 값 com.mysql.jdbc.Driver로 치환됩니다.
// 타입변환을 스프링이 처리하므로 Stirng타입 com.mysql... 이 아닌 실제 클래스 오브젝트로 치환됩니다.
@Bean
public DataSource dataSource(){
Simple...
ds.setDriverClss(this.driverClass);
}
@Bean
public static PropetySourcesPlaceholderConfigurer placeholderConfigurer(){
return new PropertySour...();
// 반드시 스태틱메소드로 선언되야 합니다.
}
}
6-6. 빈 설정의 재사용과 Enable 애노테이션
SQL서비스와 관련된 빈 설정정보는 재사용 가능하도록 분리했습니다. SqlSerice만 DAO에 노출하면되고 나머지 구현 방법은 감춰두고 자유롭게 확장 변경 할 수 있습니다. 또, 빈 설정을 자바 클래스로 만들어뒀기 떄문에 빈 설정정보도 라이브러리와 함께 패키징해서 제공할 수 있습니다. 빈 설정정보로 xml을 사용했다면 SQL을 사용할 프로젝트(애플리케이션) 마다 빈 설정을 다시 해줘야 하는 번거로움이 있지만, 클래스로 두면서 Import 애노테이션만 추가하면 프로젝트에 빈 등록을 한번에 끝낼 수 있습니다.
다만 아직 독립적인 모듈이 되기 곤란한 부분이있습니다. OxmSqlService의 내부 클래스 OxmSqlReader클래스를 보면 Sql매핑 내역을 담은 sqlmap.xml 파일의 위치를 지정하는 부분이 있습니다.
이 매핑파일의 위치는 프로젝트마다 달라질 수 있습니다. 그렇다면 SQL 매핑 리소스는 빈 클래스 외부에서 설정할 수 있어야 합니다.
private class OxmSqlReader implements SqlReader{
...
private Resource sqlmap = new ClassPathResource("sqlmap.xml", UserDao.class);
// 위치가 UseDao클래스 루트로 고정되어 있습니다.
// "/sqlmap.xml" 만 파라미터를 두면, 디폴트 위치를 따르게 됩니다.
// 하지만 매핑 리소스와 이 빈의 의존성은 제거할 필요가 있습니다.
}
이미 sqlmap프로퍼티 값은 OxmSqlService에 있는 같은 이름의 프로퍼티를 통해 전달 받을 수 있게 해놨습니다.
@Bean
public SqlService sqlService(){
...
sqlService.setSqlmap(new ClassPathResource("sqlmap.xml", UserDao.class);
// 아직 특정 경로에 종속된 정보가 남아있습니다.
// 이대로 두면 해당코드의 수정 없이 Import로 다른 애플리케이션에서 사용할수 없습니다.
// UserDao와 의존성을 제거해야합니다.
// 매번 달라지는 정보를 담는 콜백과 달리 리소스의 위치는 바뀔일이 없습니다. -> 인터페이스/DI를 이용합니다.
}
// sqlServiceContext에서 Sql매핑파일의 위치지정을 분리합니다.
public interface SqlmapConfig{
Resource getSqlMapResource();
}
public class UserSqlmapConfig implements SqlMapConfig{
@Override
public Resource getSqlMapResource(){
return new ClassPathResource("sqlmap.xml", UserDao.class);
}
}
...
public class AppContext{
// 운영시 빈 설정정보
...
@Bean
public SqlMapConfig sqlMapConfig(){
return new UserSqlMapConfig();
}
}
@Configuration
public class SqlServiceContext{
@Autowried
SqlMapConfig sqlMapConfig;
@Bean
public SqlService sqlService(){
...
sqlServce.setSqlmap(this.sqlMapConfig.getSqlMapResource());
...
}
}
이제 SqlServiceContext 코드는 SQL매핑파일의 위치 변경에 영향을 받지 않습니다. 이처럼 설정정보를 담은 클래스도 리팩토링으로 OOP원칙을 지킬 수 있게 할 수 있습니다.
그런데 리소스 위치 하나 때문에 별도의 클래스를 만든것이 좀 못마땅합니다. UserSqlMapConfig 클래스와 빈 설정을 아주 간단히 만들 수 있는 방법이 있습니다.
우선 Configuration 애노테이션을 살펴봅니다. 이 애노테이션은 Component를 메타 애노테이션으로 갖고있어 자동등록 빈 대상이 됩니다. 그래서 AppContext도 빈으로 취급됩니다.
그래서 autowired로 주입받을 수 있습니다. 그렇다면 AppContext가 이 SqlMapConfig를 직접 구현하게 해봅니다.
하나의 빈이 꼭 한가지일 필요는 없습니다. 2-5를 참조하면 자기참조 빈을 만들면서 하나의 빈이 여러 개의 인터페이스를 구현하는 경우를 볼 수 있습니다. AppContext도 원하면 얼마든지 인터페이스를 구현하게 만들 수 있습니다. 이것을 이용해 SqlMapConfig를 구현하게해서, SqlServiceContext가 주입받게 만듭니다.
public class AppContext implements SqlMapConfig{
// 이렇게 SqlMapConfig 타입을 갖게해 직접 구현하면, UserSqlMapConfig클래스와 AppContext의 sqlMapConfig 빈 메소드를 제거합니다.
...
@Override
public Resource getSqlMapResource(){
return new Class...;
}
}
조금더 직관적으로 보기 위해서 Enable애노테이션을 활용합니다. 트랜잭션에 적용한 EnableTransactionManagement를 생각해보자. 이 애노테이션은 TransactionManagementConfigurationSelector 클래스를 Import하는 셈입니다.
스프링 3.1은 SqlServiceContext처럼 모듈화된 빈 설정을 가져올 떄 사용하는 import를 다른 애노테이션으로 대체할 수 있는 방법을 제공합니다.
Component를 메타 애노테이션으로 이용해 Service나 Repository로 직관적이게 볼 수 있게 하는 방식입니다.
@Import(value=SqlServiceContext.class)
public @interface EnableSqlService{}
// 이렇게 Enable 애노테이션을 정의하면 직관적이게 볼 수 있습니다.
...
@EnableSqlService // import를 대체합니다. SQL을 사용한다는 의미가 잘 드러납니다.
pubic class AppContext implements SqlMapConfig{
}
// 부가적으로 Import를 메타 애노테이션으로 부여하는경우 추가적인 장점이있습니다.
// 엘리먼트를 넣어서 옵션을 지정할 수 있습니다.
// SqlMapConfig를 SqlServiceContext에 DI해 리소스를 전달하던 방식을
@EnableSqlService("classpath:/springbook/user/sqlmap.xml")
// 이렇게 간결하게 만들 수 있습니다.
지금까지 xml의 설정정보를 자바 클래스와 애노테이션으로 바꾸고, 자동등록과 자동와이어링을 적용하고, 실행환경에 따라 달라지는 빈 설정정보를 분리해서 프로파일로 적용하고, 프로퍼티 소스를 통해 외부 서비스 접속에 필요한 정보는 빈 설정에서 사용하게 했습니다. 마지막으로, 독립적으로 재사용 가능한 코드와 설정정보를 분리해내, 손쉽게 가져다 쓸 수 있는 전용 애노테이션도 만들었습니다.
7.정리
- SQL처럼 변경될 수 있는 텍스트 정보는 외부 리소스에 담아두고 가져오게 만들면 좋다.
- 성격이 다른 코드가 한데 섞여있는 클래스는 성격별로 인터페이스를 정의해서 분리하는게 좋다.
- 다른 인터페이스에 속한 기능은 해당 인터페이스를 통해서만 접근가능하게 만들고, 자기참조 빈으로 의존관계를 만들어 검증한다.
- 검증을 마쳤으면 클래스를 분리하는 것도 고려할 수 있다.
- 자주 사용되는 의존 오브젝트는 디폴트로 정의해두면 편하다.
- XML과 오브젝트의 매핑은 스프링의 OXM추상화 기능을 활용한다.
- 특정 의존 오브젝트를 고정시켜 특화하려면 멤버 클래스로 만드는 것이 편리하다.
- 기존에 만들어진 기능과 중복되면 위임을 통해 제거한다.
- 외부 리소스를 사용하는 코드에서는 스프링의 리소스 추상화와 리소스 로더를 사용한다.
- 인터페이스/DI를 의식하면서 객체지향 설계에 도움이되게 한다.
- 클라이언트에 따라서 인터페이스를 분리할 때, 새로운 인터페이스를 만드는 것과 인터페이스를 상속하는 것 두가지를 사용할 수 있다.
- 애플리케이션에서 내장하는 DB를 사용할때는 스프링의 내장형 DB추상화 기능과 전용 태그를 사용한다.

댓글남기기